
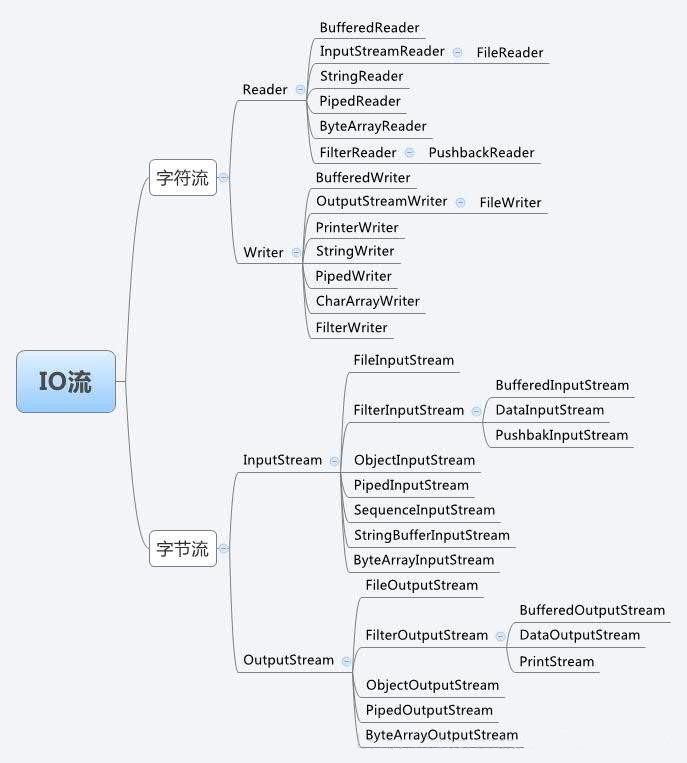
字节流
InputStream
public abstract class InputStreamextends Objectimplements Closeable
此抽象类是表示字节输入流的所有类的超类。
需要定义 InputStream 的子类的应用程序必须始终提供返回下一个输入字节的方法。
FileInputStream
public class FileInputStreamextends InputStream
FileInputStream 从文件系统中的某个文件中获取输入字节。哪些文件可用取决于主机环境。
FileInputStream 用于读取诸如图像数据之类的原始字节流。要读取字符流,请考虑使用 FileReader。
常用构造方法
public FileInputStream(File file)
通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的 File 对象 file 指定。创建一个新 FileDescriptor 对象来表示此文件连接。
file - 为了进行读取而打开的文件。
首先,如果有安全管理器,则用 file 参数表示的路径作为参数调用其 checkRead 方法。
如果指定文件不存在,或者它是一个目录,而不是一个常规文件,抑或因为其他某些原因而无法打开进行读取,则抛出 FileNotFoundException。
public FileInputStream(File file) throws FileNotFoundException {
String name = (file != null ? file.getPath() : null);
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkRead(name);
}
if (name == null) {
throw new NullPointerException();
}
if (file.isInvalid()) {
throw new FileNotFoundException("Invalid file path");
}
fd = new FileDescriptor();
fd.attach(this);
path = name;
open(name);
}
public FileInputStream(String name)
通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的路径名 name 指定。创建一个新 FileDescriptor 对象来表示此文件连接。
name - 与系统有关的文件名。
首先,如果有安全管理器,则用 name 作为参数调用其 checkRead 方法。
如果指定文件不存在,或者它是一个目录,而不是一个常规文件,抑或因为其他某些原因而无法打开进行读取,则抛出 FileNotFoundException。
public FileInputStream(String name) throws FileNotFoundException {
//调用构造方法FileInputStream(file)
this(name != null ? new File(name) : null);
}
常用方法
public int read()
从此输入流中读取一个数据字节。如果没有输入可用,则此方法将阻塞。
该方法返回下一个数据字节;如果已到达文件末尾,则返回 -1。
FileInputStream fis = new FileInputStream(new File("text.txt"));
int c = 0;
while((c = fis.read()) != -1) {
System.out.print((char)c);
}
fis.close();
public int read(byte[] b)
从此输入流中将最多 b.length 个字节的数据读入一个字节数组中。在某些输入可用之前,此方法将阻塞。
b - 存储读取数据的缓冲区。
该方法返回读入缓冲区的字节总数,如果因为已经到达文件末尾而没有更多的数据,则返回 -1。
FileInputStream fis = new FileInputStream(new File("text.txt"));
byte[] b = new byte[1024];
while(fis.read(b) != -1){
System.out.print(new String(b));
}
fis.close();
//read(b)由read(byte[] b,int off,int len)方法实现
public int read(byte b[]) throws IOException {
return readBytes(b, 0, b.length);
}
public int read(byte[] b,int off,int len)
从此输入流中将最多 len 个字节的数据读入一个字节数组中。在某些输入可用之前,此方法将阻塞。
b - 存储读取数据的缓冲区。
off - 数据的起始偏移量。
len - 读取的最大字节数。
FileInputStream fis = new FileInputStream(new File("text.txt"));
byte[] b = new byte[10];
while(fis.read(b,0,5) != -1){
System.out.print(new String(b));
}
fis.close();
//输出 01234 56789
//注:text.txt内容为:0123456789
根据输出结果和几次测试,我个人总结为:b为读取数据的缓冲区,用于存放fis读取的数;len为每次读取文件的文件指针移动距离,即每次读取多少长度的数据;off为b中数据数据存入的起始位置,即数据存入数组时的起始下标。如上述案例所示,byte数组长度为10,fis.read(b,0,5) 则表示每次从文本中读取len(即5)个长度的数据(即01234),从下标为0的位置开始放入数据(即b:[0,1,2,3,4, , , , , , ];如果off的值为5,则b:[ , , , , ,0,1,2,3,4];如果off+len>b.length,则会造成数组越界异常,因为此时数组中起始之后的剩余位置已经不够存放读取的数据)。
BufferedInputStream
作为另一种输入流,BufferedInputStream 为添加了功能,即缓冲输入和支持 mark 和 reset 方法的能力。创建 BufferedInputStream 时即创建了一个内部缓冲区数组。读取或跳过流中的各字节时,必要时可根据所包含的输入流再次填充该内部缓冲区,一次填充多个字节。mark 操作记录输入流中的某个点,reset 操作导致在从所包含的输入流中获取新的字节前,再次读取自最后一次 mark 操作以来所读取的所有字节。
protected byte[] buf - 存储数据的内部缓冲区数组。
protected int count - 比缓冲区中最后一个有效字节的索引大一的索引。
protected int marklimit - 调用 mark 方法后,在后续调用 reset 方法失败前所允许的最大提前读取量。
protected int markpos - 最后一次调用 mark 方法时 pos 字段的值。
protected int pos - 缓冲区中的当前位置。
常用构造方法
public BufferedInputStream(InputStream in)
创建 BufferedInputStream 并保存其参数,即输入流 in,以便将来使用。创建一个内部缓冲区数组并将其存储在 buf 中。
in - 基础输入流。
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
//调用BufferedInputStream(InputStream in,int size)构造方法,并设置size为8192
}
public BufferedInputStream(InputStream in,int size)
创建具有指定缓冲区大小的 BufferedInputStream,并保存其参数,即输入流 in,以便将来使用。创建一个长度为 size 的内部缓冲区数组并将其存储在 buf 中。
in - 基础输入流。 size - 缓冲区的大小。
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
常用方法
public int read()
参见 InputStream 的 read 方法的常规协定。用法应该与InputStream的read()方法相同。
public int read(byte[] b,int off,int len)
在此字节输入流中从给定的偏移量开始将各字节读取到指定的 byte 数组中。
此方法实现了相应 InputStream 类的 read 方法的常规协定。另一个便捷之处在于,它会尝试尽可能多的读取字节,方法是重复地调用基础流的 read 方法。这种迭代的 read 会一直继续下去,直到满足下列某个条件:
-
已经读取了指定的字节数,
-
基础流的 read 方法返回 -1,指示文件末尾(end-of-file),或者
-
基础流的 available 方法返回零,指示将阻塞进一步的输入请求。
如果在基础流上第一次调用 read 返回 -1(指示文件末尾),则此方法返回 -1。否则此方法返回实际读取的字节数。
鼓励(但不是必须)此类的各个子类以相同的方式尝试读取尽可能多的字节。
该方法覆盖了FileInputStream中的read方法,返回读取的字节数,如果已到达流末尾,则返回 -1。
OutputStream
public abstract class OutputStreamextends Objectimplements Closeable, Flushable
此抽象类是表示输出字节流的所有类的超类。输出流接受输出字节并将这些字节发送到某个接收器。
需要定义 OutputStream 子类的应用程序必须始终提供至少一种可写入一个输出字节的方法。
FileOutputStream
public class FileOutputStreamextends OutputStream
文件输出流是用于将数据写入 File 或 FileDescriptor 的输出流。文件是否可用或能否可以被创建取决于基础平台。特别是某些平台一次只允许一个 FileOutputStream(或其他文件写入对象)打开文件进行写入。在这种情况下,如果所涉及的文件已经打开,则此类中的构造方法将失败。
FileOutputStream 用于写入诸如图像数据之类的原始字节的流。要写入字符流,请考虑使用 FileWriter。
常用构造方法
public FileOutputStream(String name)
创建一个向具有指定名称的文件中写入数据的输出文件流。创建一个新 FileDescriptor 对象来表示此文件连接。
name - 与系统有关的文件名
首先,如果有安全管理器,则用 name 作为参数调用 checkWrite 方法。
如果该文件存在,但它是一个目录,而不是一个常规文件;或者该文件不存在,但无法创建它;抑或因为其他某些原因而无法打开它,则抛出 FileNotFoundException。
public FileOutputStream(String name) throws FileNotFoundException {
//其内部调用的是构造方法FileOutputStream(file,append)
//其中append值默认设置为false
this(name != null ? new File(name) : null, false);
}
public FileOutputStream(File file)
创建一个向指定 File 对象表示的文件中写入数据的文件输出流。创建一个新 FileDescriptor 对象来表示此文件连接。
file - 为了进行写入而打开的文件。
首先,如果有安全管理器,则用 file 参数表示的路径作为参数来调用 checkWrite 方法。
如果该文件存在,但它是一个目录,而不是一个常规文件;或者该文件不存在,但无法创建它;抑或因为其他某些原因而无法打开,则抛出 FileNotFoundException。
public FileOutputStream(File file) throws FileNotFoundException {
//其内部调用的是构造方法FileOutputStream(file,append)
//其中append值默认设置为false
this(file, false);
}
public FileOutputStream(String name,boolean append)
创建一个向具有指定 name 的文件中写入数据的输出文件流。如果第二个参数为 true,则将字节写入文件末尾处,而不是写入文件开始处。创建一个新 FileDescriptor 对象来表示此文件连接。
name - 与系统有关的文件名
append - 如果为 true,则将字节写入文件末尾处,而不是写入文件开始处
首先,如果有安全管理器,则用 name 作为参数调用 checkWrite 方法。
如果该文件存在,但它是一个目录,而不是一个常规文件;或者该文件不存在,但无法创建它;抑或因为其他某些原因而无法打开它,则抛出 FileNotFoundException。
public FileOutputStream(String name, boolean append) throws FileNotFoundException{
//其内部实现也是调用构造函数FileOutputStream(file,append)
this(name != null ? new File(name) : null, append);
}
public FileOutputStream(File file,boolean append)
创建一个向指定 File 对象表示的文件中写入数据的文件输出流。如果第二个参数为 true,则将字节写入文件末尾处,而不是写入文件开始处。创建一个新 FileDescriptor 对象来表示此文件连接。
file - 为了进行写入而打开的文件。 append - 如果为 true,则将字节写入文件末尾处,而不是写入文件开始处
首先,如果有安全管理器,则用 file 参数表示的路径作为参数来调用 checkWrite 方法。
如果该文件存在,但它是一个目录,而不是一个常规文件;或者该文件不存在,但无法创建它;抑或因为其他某些原因而无法打开它,则抛出 FileNotFoundException。
public FileOutputStream(File file, boolean append) throws FileNotFoundException {
String name = (file != null ? file.getPath() : null);
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkWrite(name);
}
if (name == null) {
throw new NullPointerException();
}
if (file.isInvalid()) {
throw new FileNotFoundException("Invalid file path");
}
this.fd = new FileDescriptor();
fd.attach(this);
this.append = append;
this.path = name;
open(name, append);
}
常用方法
public void write(int b)
将指定字节写入此文件输出流。实现 OutputStream 的 write 方法。
b - 要写入的字节。
//append值默认为false,表示覆盖写。true则为追加
FileOutputStream fos = new FileOutputStream("text.txt");
fos.write(65);//A的acsii值为65
fos.close();
//text.txt中内容为A
//其内部实现为如下,其中append值在调用构造方法时已默认设置为false
public void write(int b) throws IOException {
write(b, append);
}
public void write(byte[] b)
将 b.length 个字节从指定字节数组写入此文件输出流中。
b - 数据。
//append值默认为false,表示覆盖写。true则为追加
FileOutputStream fos = new FileOutputStream("text.txt");
fos.write("AAA".getBytes());
fos.close();
//text.txt中内容为AAA
//其内部实现为调用方法writeBytes(b,off,len,append)
//其中append值在调用构造方法时已默认设置为false
public void write(byte b[]) throws IOException {
writeBytes(b, 0, b.length, append);
}
public void write(byte[] b,int off,int len)
将指定字节数组中从偏移量 off 开始的 len 个字节写入此文件输出流。
b - 数据。 off - 数据中的起始偏移量。 len - 要写入的字节数。
//append值默认为false,表示覆盖写。true则为追加
FileOutputStream fos = new FileOutputStream("text.txt");
byte[] b = "0123456789".getBytes();
fos.write(b, 0, 10);
fos.close();
//text.txt中内容为0123456789
FileOutputStream的write(b,off,len)方法其实与FileInputStream的read(b,off,len)方法很相似。只不过write方法是将b中的数据写到文件中去。b 表示需要写入文件的数据;off 为需要写入数据的起始偏移量,即以数组b的off下标位作为数据写入的起始点;len 一次写入的字节数,即一次写入从b的off下标位开始到off+len位结束。write(b,0,10) 即表示所写入的数据为:数组b的第0位直到第0+10位(即0123456789)。同理,write(b,5,5) 即表示所写入的数据为:数组b的第5位直到第5+5位(即56789)。write(b,5,3) 则是第5位到第5+3位(即567)。与read方法相似,若off + len > b.length ,则会造成数组越界异常。
BufferedOutputStream
public class BufferedOutputStreamextends FilterOutputStream
该类实现缓冲的输出流。通过设置这种输出流,应用程序就可以将各个字节写入基础输出流中,而不必为每次字节写入调用基础系统。
protected byte[] buf - 存储数据的内部缓冲区。
protected int count - 缓冲区中的有效字节数。
常用构造方法
BufferedOutputStream(OutputStream out)
创建一个新的缓冲输出流,以将数据写入指定的基础输出流。
out - 基础输出流。
public BufferedOutputStream(OutputStream out) {
//其内部实现是调用构造函数BufferedOutputStream(out,size)
//size值默认为8192
this(out, 8192);
}
BufferedOutputStream(OutputStream out, int size)
创建一个新的缓冲输出流,以将具有指定缓冲区大小的数据写入指定的基础输出流。
out - 基础输出流。 size - 缓冲区的大小。
public BufferedOutputStream(OutputStream out, int size) {
super(out);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
常用方法
public void write(int b)
将指定的字节写入此缓冲的输出流。
b - 要写入的字节。
//append值默认为false,表示覆盖写。true则为追加
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("text.txt"));
bos.write(65);//A的acsii值为65
bos.close();
//text.txt文件内容为 A
//其内部实现如下
public synchronized void write(int b) throws IOException {
if (count >= buf.length) {
flushBuffer();
}
buf[count++] = (byte)b;
}
public void write(byte[] b,int off,int len)
将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此缓冲的输出流。
b - 数据。
off - 数据的起始偏移量。 len - 要写入的字节数。
一般来说,此方法将给定数组的字节存入此流的缓冲区中,根据需要将该缓冲区刷新,并转到基础输出流。但是,如果请求的长度至少与此流的缓冲区大小相同,则此方法将刷新该缓冲区并将各个字节直接写入基础输出流。因此多余的 BufferedOutputStream 将不必复制数据。
用法与FileOutputStream的write(b,off,len)相似。其内部实现如下:
public synchronized void write(byte b[], int off, int len) throws IOException {
if (len >= buf.length) {
flushBuffer();
out.write(b, off, len);
return;
}
if (len > buf.length - count) {
flushBuffer();
}
System.arraycopy(b, off, buf, count, len);
count += len;
}
public void flush()
刷新此缓冲的输出流。这迫使所有缓冲的输出字节被写出到基础输出流中。
其内部实现如下:
public synchronized void flush() throws IOException {
flushBuffer();
out.flush();
}
private void flushBuffer() throws IOException {
if (count > 0) {
out.write(buf, 0, count);
count = 0;
}
}
字符流
Reader
public abstract class Readerextends Objectimplements Readable, Closeable
用于读取字符流的抽象类。子类必须实现的方法只有 read(char[], int, int) 和 close()。但是,多数子类将重写此处定义的一些方法,以提供更高的效率和/或其他功能。
InputStreamReader
public class InputStreamReader extends Reader
InputStreamReader 是字节流通向字符流的桥梁:它使用指定的 charset 读取字节并将其解码为字符。它使用的字符集可以由名称指定或显式给定,否则可能接受平台默认的字符集。
每次调用 InputStreamReader 中的一个 read() 方法都会导致从基础输入流读取一个或多个字节。要启用从字节到字符的有效转换,可以提前从基础流读取更多的字节,使其超过满足当前读取操作所需的字节。
为了达到最高效率,可要考虑在 BufferedReader 内包装 InputStreamReader。例如:
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
常用构造方法
public InputStreamReader(InputStream in)
创建一个使用默认字符集的 InputStreamReader。
in - InputStream
public InputStreamReader(InputStream in) {
super(in);
try {
sd = StreamDecoder.forInputStreamReader(in, this, (String)null);
} catch (UnsupportedEncodingException e) {
// The default encoding should always be available
throw new Error(e);
}
}
public InputStreamReader(InputStream in,String charsetName)
创建使用指定字符集的 InputStreamReader。
in - InputStream
charsetName - 受支持的 charset 的名称
public InputStreamReader(InputStream in, String charsetName) throws UnsupportedEncodingException {
super(in);
if (charsetName == null)
throw new NullPointerException("charsetName");
sd = StreamDecoder.forInputStreamReader(in, this, charsetName);
}
常用方法
public String getEncoding()
返回此流使用的字符编码的名称。
如果该编码有历史上用过的名称,则返回该名称;否则返回该编码的规范化名称。
如果使用 InputStreamReader(InputStream, String) 构造方法创建此实例,则返回的由此编码生成的唯一名称可能与传递给该构造方法的名称不一样。如果流已经关闭,则此方法可能返回 null。
//text.txt使用的编码格式为GBK。
InputStreamReader isr = new InputStreamReader(new FileInputStream("text.txt"));
System.out.println(isr.getEncoding());
isr.close();
//输出 GBK
//注:在修改text.txt的编码格式为UTF-8后,依旧输出GBK。说明其返回的并不是文件的编码格式
public int read()
读取单个字符。
返回读取的字符,如果已到达流的末尾,则返回 -1。
//text.txt内容为:零一二三四五六七八九十
InputStreamReader isr = new InputStreamReader(new FileInputStream("text.txt"));
int c;
while((c = isr.read()) != -1) {
System.out.print((char)c);
}
//输出:零一二三四五六七八九十
//Reader类中的read()方法如下:
public int read() throws IOException {
char cb[] = new char[1];
if (read(cb, 0, 1) == -1)
return -1;
else
return cb[0];
}
public int read(char[] cbuf,int offset,int length)
将字符读入数组中的某一部分。
cbuf - 目标缓冲区 offset - 以其处开始存储字符的偏移量 length - 要读取的最大字符数
//text.txt内容为:零一二三四五六七八九十
InputStreamReader isr = new InputStreamReader(new FileInputStream("text.txt"));
char[] cbuf = new char[10];
//isr.read(cbuf) => isr.read(cbuf,0,cbuf.length)
isr.read(cbuf, 5, 5);
System.out.println(new String(cbuf));
isr.close();
//输出: 零一二三四
从上述案例可以看出,字符流的read(cbuf,offset,length)方法和字节流的read(b,off,len)方法很相似,区别在于读取的是字符还是字节。cbuf为读取字符的缓冲区;offset为字符存入数组时的起始位置;length为每次读取的最大字符数。与字节流read方法同理,read(cbuf,5,3) 输出: 零一二 。与字节流一样,若offset+length > cbuf.length ,则会出现数组越界异常。
FileReader
public class FileReaderextends InputStreamReader
用来读取字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是适当的。要自己指定这些值,可以先在 FileInputStream 上构造一个 InputStreamReader。
FileReader 用于读取字符流。要读取原始字节流,请考虑使用 FileInputStream。
常用构造方法
public FileReader(String fileName)
在给定从中读取数据的文件名的情况下创建一个新 FileReader。
fileName - 要从中读取数据的文件的名称
//其内部实现是调用父类的构造方法InputStreamReader(InputStream in)
public FileReader(String fileName) throws FileNotFoundException {
super(new FileInputStream(fileName));
}
public FileReader(File file)
在给定从中读取数据的 File 的情况下创建一个新 FileReader。
file - 要从中读取数据的 File
//内部实现时调用父类的构造方法InputStreamReader(InputStream in)
public FileReader(File file) throws FileNotFoundException {
super(new FileInputStream(file));
}
BufferedReader
public class BufferedReaderextends Reader
从字符输入流中读取文本,缓冲各个字符,从而提供字符、数组和行的高效读取。
可以指定缓冲区的大小,或者可使用默认的大小。大多数情况下,默认值就足够大了。当BufferedReader在读取文本文件时,会先尽量从文件中读入字符数据并放满缓冲区,而之后若使用read()方法,会先从缓冲区中进行读取。如果缓冲区数据不足,才会再从文件中读取。
通常,Reader 所作的每个读取请求都会导致对基础字符或字节流进行相应的读取请求。因此,建议用 BufferedReader 包装所有其 read() 操作可能开销很高的 Reader(如 FileReader 和 InputStreamReader)。例如,
BufferedReader in = new BufferedReader(new FileReader(“foo.in”));
将缓冲指定文件的输入。如果没有缓冲,则每次调用 read() 或 readLine() 都会导致从文件中读取字节,并将其转换为字符后返回,而这是极其低效的。
可以对使用 DataInputStream 进行按原文输入的程序进行本地化,方法是用合适的 BufferedReader 替换每个 DataInputStream。
常用构造方法
public BufferedReader(Reader in,int sz)
创建一个使用指定大小输入缓冲区的缓冲字符输入流。
in - 一个 Reader
sz - 输入缓冲区的大小
public BufferedReader(Reader in, int sz) {
//其内部调用的是父类Reader的构造方法Reader(Object lock)
super(in);
if (sz <= 0)
throw new IllegalArgumentException("Buffer size <= 0");
this.in = in;
cb = new char[sz];
nextChar = nChars = 0;
}
public BufferedReader(Reader in)
创建一个使用默认大小输入缓冲区的缓冲字符输入流。
in - 一个 Reader
public BufferedReader(Reader in) {
//其内部实现调用的是自身的构造函数BufferedReader(Reader in, int sz)
//其中defaultCharBufferSize默认大小为8192
this(in, defaultCharBufferSize);
}
常用方法
public int read()
读取单个字符。
覆盖Reader类中的read方法,返回作为范围 0 到 65535 (0x00-0xffff) 的整数读入的字符,如果已到达流末尾,则返回 -1。
//text.txt内容为:零一二三四五六七八九十
BufferedReader br = new BufferedReader(new FileReader("text.txt"));
int c;
while((c = br.read()) != -1) {
System.out.print((char)c);
}
//输出:零一二三四五六七八九十
//其内部实现如下
public int read() throws IOException {
synchronized (lock) {
ensureOpen();
for (;;) {
if (nextChar >= nChars) {
fill();
if (nextChar >= nChars)
return -1;
}
if (skipLF) {
skipLF = false;
if (cb[nextChar] == '\n') {
nextChar++;
continue;
}
}
return cb[nextChar++];
}
}
}
public int read(char[] cbuf,int off,int len)
将字符读入数组的某一部分。
cbuf - 目标缓冲区
off - 开始存储字符处的偏移量
len - 要读取的最大字符数
此方法实现相应 Reader 类的 read 方法的常规协定。另一个便捷之处在于,它会尝试尽可能多的读取字符,方法是重复地调用基础流的 read 方法。这种迭代的 read 会一直继续下去,直到满足下列某个条件:
- 已经读取了指定的字符数
- 基础流的 read 方法返回 -1,指示文件末尾(end-of-file)
- 基础流的 ready 方法返回 false,指示将阻塞进一步的输入请求。
如果在基础流上第一次调用 read 返回 -1(指示文件末尾),则此方法返回 -1。否则,此方法返回实际读取的字符数。
鼓励(但不是必须)此类的各个子类以相同的方式尝试读取尽可能多的字符。
一般来说,此方法从此流的字符缓冲区中获得字符,根据需要从基础流中填充缓冲区。但是,如果缓冲区为空、标记无效,并且所请求的长度至少与缓冲区相同,则此方法将直接从基础流中将字符读取到给定的数组中。因此多余的 BufferedReader 将不必复制数据。
返回读取的字符数,如果已到达流末尾,则返回 -1
//text.txt内容为:零一二三四五六七八九十
BufferedReader br = new BufferedReader(new FileReader("text.txt"));
char[] cbuf = new char[11];
br.read(cbuf, 0, cbuf.length);
System.out.println(new String(cbuf));
br.close();
//输出: 零一二三四五六七八九十
//其内部实现如下
public int read(char cbuf[], int off, int len) throws IOException {
synchronized (lock) {
ensureOpen();
if ((off < 0) || (off > cbuf.length) || (len < 0) ||
((off + len) > cbuf.length) || ((off + len) < 0)) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int n = read1(cbuf, off, len);
if (n <= 0) return n;
while ((n < len) && in.ready()) {
int n1 = read1(cbuf, off + n, len - n);
if (n1 <= 0) break;
n += n1;
}
return n;
}
}
public String readLine()
读取一个文本行。通过下列字符之一即可认为某行已终止:换行 (‘\n’)、回车 (‘\r’) 或回车后直接跟着换行。
返回包含该行内容的字符串,不包含任何行终止符,如果已到达流末尾,则返回 null。
//text.txt内容为:零一二三四五六七八九十
// 零一二三四五六七八九十
BufferedReader br = new BufferedReader(new FileReader("text.txt"));
String line;
while((line = br.readLine()) != null) {
System.out.println(line);
}
br.close();
//输出: 零一二三四五六七八九十
// 零一二三四五六七八九十
Writer
public abstract class Writerextends Objectimplements Appendable, Closeable, Flushable
写入字符流的抽象类。子类必须实现的方法仅有 write(char[], int, int)、flush() 和 close()。但是,多数子类将重写此处定义的一些方法,以提供更高的效率和/或其他功能。
OutputStreamWriter
public class OutputStreamWriter extends Writer
OutputStreamWriter 是字符流通向字节流的桥梁:使用指定的 charset 将要向其写入的字符编码为字节。它使用的字符集可以由名称指定或显式给定,否则可能接受平台默认的字符集。
每次调用 write() 方法都会针对给定的字符(或字符集)调用编码转换器。在写入基础输出流之前,得到的这些字节会在缓冲区累积。可以指定此缓冲区的大小,不过,默认的缓冲区对多数用途来说已足够大。注意,传递到此 write() 方法的字符是未缓冲的。
为了达到最高效率,可考虑将 OutputStreamWriter 包装到 BufferedWriter 中以避免频繁调用转换器。例如:
Writer out = new BufferedWriter(new OutputStreamWriter(System.out));
代理对 是一个字符,它由两个 char 值序列表示:高 代理项的范围为 ‘\uD800’ 到 ‘\uDBFF’,它后面跟着范围为 ‘\uDC00’ 到 ‘\uDFFF’ 的低 代理项。如果由代理项对表示的字符无法由给定的字符集编码,则把依赖于字符集的替代序列 写入输出流。
错误代理元素 指的是后面不跟低代理项的高代理项,或前面没有高代理项的低代理项。尝试写入包含错误代理元素的字符流是非法的。写入错误代理元素时,此类实例的行为是不确定的。
常用构造方法
public OutputStreamWriter(OutputStream out,Charset cs)
创建使用给定字符集的 OutputStreamWriter。
out - OutputStream cs - 字符集
public OutputStreamWriter(OutputStream out) {
super(out);
try {
se = StreamEncoder.forOutputStreamWriter(out, this, (String)null);
} catch (UnsupportedEncodingException e) {
throw new Error(e);
}
}
public OutputStreamWriter(OutputStream out,CharsetEncoder enc)
创建使用给定字符集编码器的 OutputStreamWriter。
out - OutputStream enc - 字符集编码器
public OutputStreamWriter(OutputStream out, String charsetName) throws UnsupportedEncodingException{
super(out);
if (charsetName == null)
throw new NullPointerException("charsetName");
se = StreamEncoder.forOutputStreamWriter(out, this, charsetName);
}
常用方法
public String getEncoding()
返回此流使用的字符编码的名称。
如果此编码具有历史名称,则返回该名称;否则返回该编码的规范化名称。
如果此实例是用 OutputStreamWriter(OutputStream, String) 构造方法创建的,则返回的由此编码生成的惟一名称可能与传递给该构造方法的名称不一样。如果流已经关闭,则此方法可能返回 null。
返回此编码的历史名称,如果流已经关闭,则可能返回 null。
public void write(int c)
写入单个字符。
c - 指定要写入字符的 int。
覆盖Writer中的write。
public void write(char[] cbuf,int off,int len)
写入字符数组的某一部分。
cbuf - 字符缓冲区 off - 开始写入字符处的偏移量 len - 要写入的字符数
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("text.txt"));
char[] cbuf = "零一二三四五六七八九十".toCharArray();
osw.write(cbuf,5,5);
osw.close();
与字节流相似,cbuf代表字符缓冲区数组,里面是待写入的字符;off表示待写入数据数组的起始位置;而len则表示待写入数据的数量。
public void write(String str,int off,int len)
写入字符串的某一部分。
str - 字符串 off - 开始写入字符的偏移量 len - 要写入的字符数
用法与write(char[] cbuf,int off,int len)相似。
FileWriter
public class FileWriter extends OutputStreamWriter
用来写入字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是可接受的。要自己指定这些值,可以先在 FileOutputStream 上构造一个 OutputStreamWriter。
文件是否可用或是否可以被创建取决于基础平台。特别是某些平台一次只允许一个 FileWriter(或其他文件写入对象)打开文件进行写入。在这种情况下,如果所涉及的文件已经打开,则此类中的构造方法将失败。
FileWriter 用于写入字符流。要写入原始字节流,请考虑使用 FileOutputStream。
常用构造方法
public FileWriter(String fileName)
在给出文件名的情况下构造一个 FileWriter 对象。
fileName - 一个字符串,表示与系统有关的文件名。
public FileWriter(String fileName) throws IOException {
//其内部实现时调用父类OutputStreamWriter的构造方法
//并new一个FileOutputSteam
super(new FileOutputStream(fileName));
}
public FileWriter(String fileName,boolean append)
在给出文件名的情况下构造 FileWriter 对象,它具有指示是否挂起写入数据的 boolean 值。
fileName - 一个字符串,表示与系统有关的文件名。 append - 一个 boolean 值,如果为 true,则将数据写入文件末尾处,而不是写入文件开始处。
public FileWriter(String fileName, boolean append) throws IOException {
//其内部实现时调用父类OutputStreamWriter的构造方法
//并在构建FileOutputStream是传入append参数
super(new FileOutputStream(fileName, append));
}
public FileWriter(File file)
在给出 File 对象的情况下构造一个 FileWriter 对象。
file - 要写入数据的 File 对象。
public FileWriter(File file) throws IOException {
//其内部实现时调用父类OutputStreamWriter的构造方法
super(new FileOutputStream(file));
}
public FileWriter(File file,boolean append)
在给出 File 对象的情况下构造一个 FileWriter 对象。如果第二个参数为 true,则将字节写入文件末尾处,而不是写入文件开始处。
file - 要写入数据的 File 对象 append - 如果为 true,则将字节写入文件末尾处,而不是写入文件开始处
public FileWriter(File file, boolean append) throws IOException {
//其内部实现时调用父类OutputStreamWriter的构造方法
//并在构建FileOutputStream是传入append参数
super(new FileOutputStream(file, append));
}
BufferedWriter
public class BufferedWriter extends Writer
将文本写入字符输出流,缓冲各个字符,从而提供单个字符、数组和字符串的高效写入。
可以指定缓冲区的大小,或者接受默认的大小。在大多数情况下,默认值就足够大了。
该类提供了 newLine() 方法,它使用平台自己的行分隔符概念,此概念由系统属性 line.separator 定义。并非所有平台都使用新行符 (‘\n’) 来终止各行。因此调用此方法来终止每个输出行要优于直接写入新行符。
通常 Writer 将其输出立即发送到基础字符或字节流。除非要求提示输出,否则建议用 BufferedWriter 包装所有其 write() 操作可能开销很高的 Writer(如 FileWriters 和 OutputStreamWriters)。例如,
PrintWriter out = new PrintWriter(new BufferedWriter(new FileWriter(“foo.out”)));
将缓冲 PrintWriter 对文件的输出。如果没有缓冲,则每次调用 print() 方法会导致将字符转换为字节,然后立即写入到文件,而这是极其低效的。
常用构造方法
public BufferedWriter(Writer out)
创建一个使用默认大小输出缓冲区的缓冲字符输出流。
out - 一个 Writer
public BufferedWriter(Writer out) {
//BufferedWriter(Writer out,int sz)
//并且传入默认sz为8192
this(out, defaultCharBufferSize);
}
public BufferedWriter(Writer out,int sz)
创建一个使用指定大小输出缓冲区的新缓冲字符输出流。
out - 一个 Writer sz - 输出缓冲区的大小,是一个正整数
public BufferedWriter(Writer out, int sz) {
//此处是调用父类Writer的构造方法
super(out);
if (sz <= 0)
throw new IllegalArgumentException("Buffer size <= 0");
this.out = out;
cb = new char[sz];
nChars = sz;
nextChar = 0;
lineSeparator = java.security.AccessController.doPrivileged(new sun.security.action.GetPropertyAction("line.separator"));
}
常用方法
public void write(int c)
写入单个字符。
c - 指定要写入字符的 int。
覆盖类 Writer 中的 write方法。
public void write(char[] cbuf,int off,int len)
写入字符数组的某一部分。
cbuf - 字符数组 off - 开始读取字符处的偏移量 len - 要写入的字符数
一般来说,此方法将给定数组的字符存入此流的缓冲区中,根据需要刷新该缓冲区,并转到基础输出流。但是,如果请求的长度至少与此缓冲区大小相同,则此方法将刷新该缓冲区并将各个字符直接写入基础流。因此多余的 BufferedWriter 将不必复制数据。
用法与FileWriter的write(char[] cbuf,int off,int len)相似。
public void write(String s,int off,int len)
写入字符串的某一部分。
s - 要写入的字符串 off - 开始读取字符处的偏移量 len - 要写入的字符数
如果 len 参数的值为负数,则不写入任何字符。这与超类中此方法的规范正好相反,它要求抛出 IndexOutOfBoundsException。
用法与FileWriter类的write(String s,int off,int len)相似。
public void newLine()
写入一个行分隔符。行分隔符字符串由系统属性 line.separator 定义,并且不一定是单个新行 (‘\n’) 符。
public void newLine() throws IOException {
//lineSeparator = java.security.AccessController.doPrivileged(new sun.security.action.GetPropertyAction("line.separator"));
write(lineSeparator);
}




