
Kubernetes简介
Kubernetes(简称k8s)是一个基于容器的分布式架构的系统支撑平台。它具备完备的集群管理能力:
- 多层次的安全防护和准入机制
- 多租户应用支撑能力(同时运行多种应用,相互影响小)
- 透明的服务注册能力和服务发现机制
- 强大的故障发现和自我修复能力
- 服务滚动升级和在线调度机制
- 可扩展的资源自动调度机制
- 多粒度的资源配额管理能力
k8s还具备完善的管理工具,可以在上面进行部署测试、运维监控等各个环节。
架构
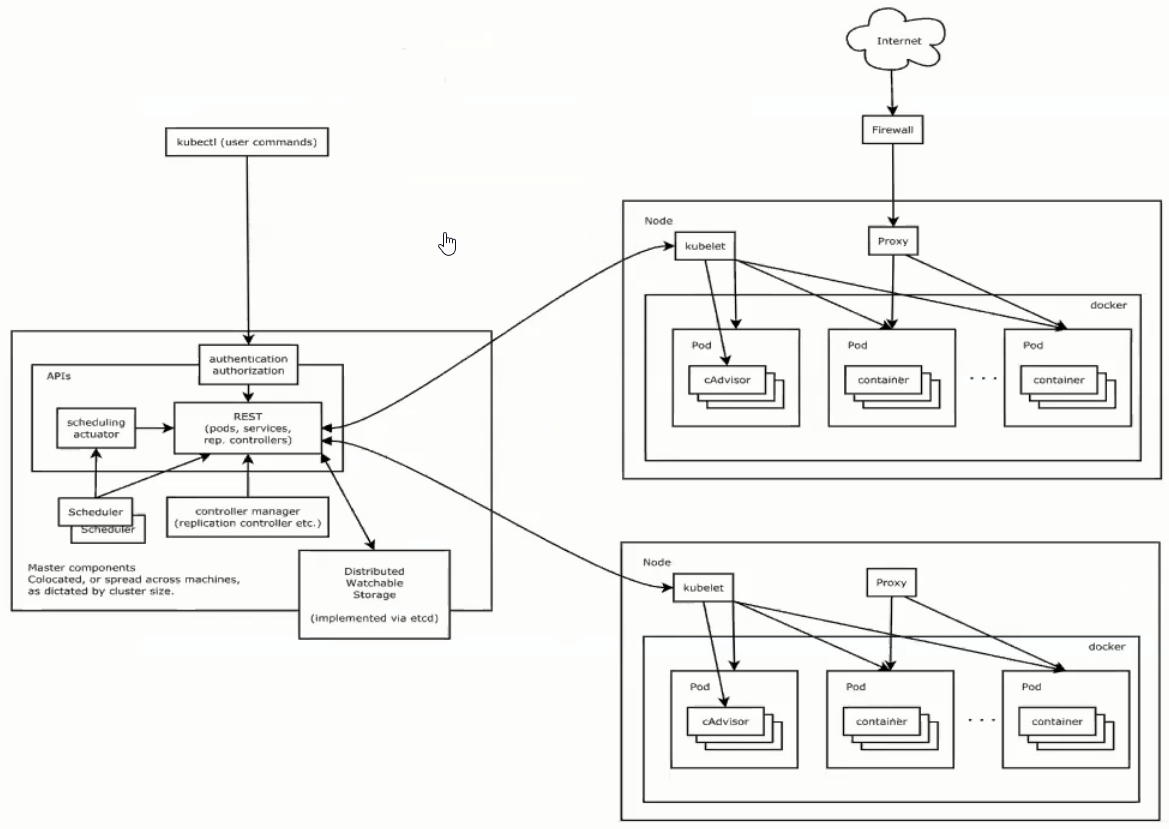
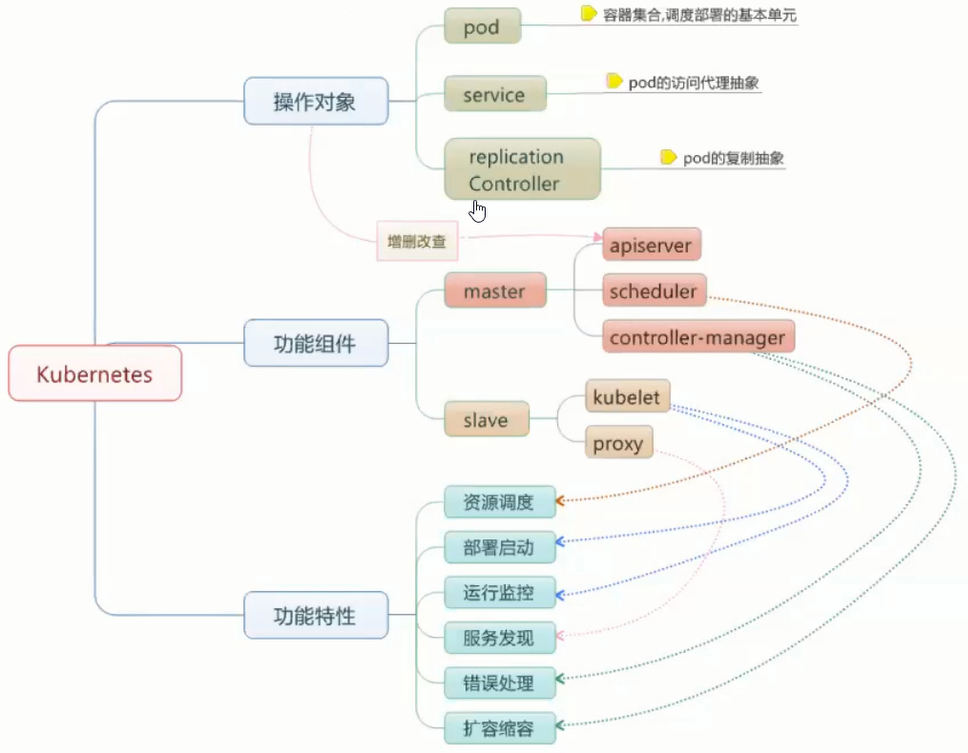
-
kubectl:k8s的sdk(对接k8s)
-
API Server:信息交流站(唯一的准入入口)
- authentication authorization:权限验证(token)
- schedule actuator:调度机制
-
Node:
- kubelet:接收处理master发出的指令和任务
- proxy:网络通信代理
-
Pod:容器集群,调度的基本单位。(机器、容器,一般是单个服务)
-
Service:网络代理,pod的访问代理
-
Replication Controller:RC,控制Pod数量
-
Scheduler:Pod的调度
API Server
特性:
- 提供了各类资源对象(如Pod、RC、Service)的增删改查以及监控等RESTful接口。是模块间的数据交互和通讯枢纽
- k8s的集群管理和API入口
- 提供完善的集群安全机制,包括认证授权、数据校验以及集群状态变更等
安全机制:
- 可以开启HTTPS安全端口(–sercure-port=6443)启动安全机制
- 选择性的暴露部分REST接口,启动一个内部代理,过滤掉不想被访问的REST API
- 开启白名单,限制特定IP访问。–accept-hosts=“”
集群模块之间的通信:
- 集群内的各个功能模块通过API Server将信息存入ETCD,当需要获取和操作这些数据时,则通过API Server提供的REST接口(GET、LIST、WATCH方法)来实现,从而实现各个模块之间的信息交互。
- 为了缓解集群中各模块对API Server的访问压力,模块都采用了缓存机制来缓存数据,模块从API Server获取到数据后,会保存到本地缓存,在某些情况下将不会之间访问API Server,二十访问缓存数据来间接访问API Server。
Controller Manager
集群内部的管理控制中心,负责集群内的Node、Pod、Endpoint、Namespace、Service、资源定额(Resource Quota)等的管理,也担当了高可用的负责人,当某个Node意外宕机时,Controller Manager会及时发现故障并自动化修复,确保集群始终处于可用的工作状态。
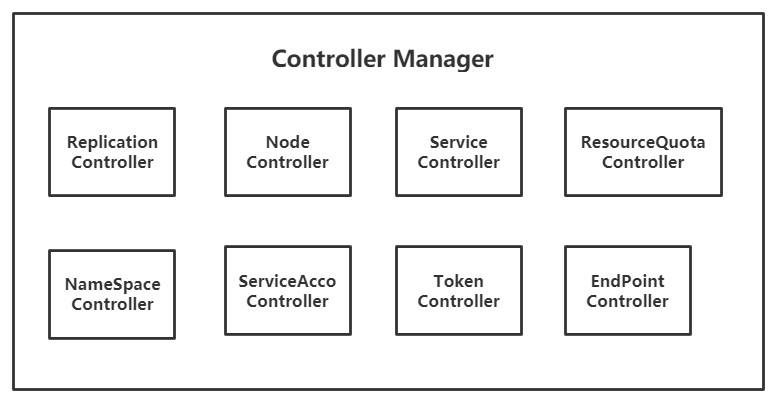
Replication Controller
简称RC,称为副本控制器,作用是保证集群中一个RC所关联的Pod副本数始终保持预设值。
职责:
- 确保集群中有且仅有N个Pod实例,N是RC中定义的Pod副本数量。
- 通过调整RC中的spec Replicas属性值来实现系统扩容或缩容。
- 通过改变RC中的Pod模板来实现系统的滚动升级。
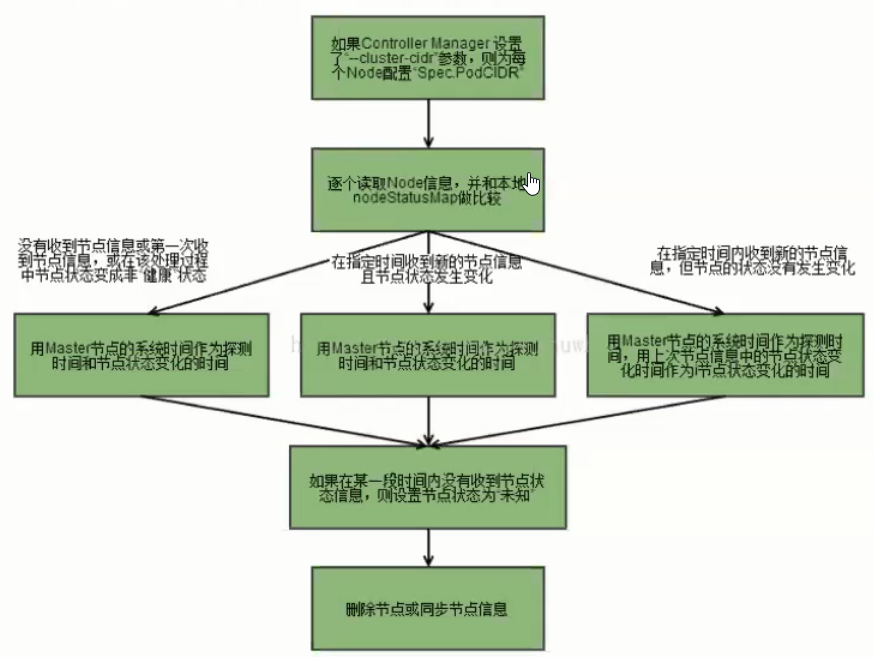
Node Controller
通过API Server实时获取Node的相关信息,实现管理和监控集群中的各个Node节点的相关控制功能。
Resource Quota Controller
资源配额管理确保指定的资源对象在任何时候都不会超量占用系统物理资源,支持三个层次的资源配置管理。
- 容器级别:对CPU和Memory进行限制。
- Pod级别:对一个Pod内所有容器的可用资源进行限制。
- Namespace级别:包括Pod数量、Replication Controller数量、Service数量、Resource Quota数量、Secret数量和可持有的PV(Persistent Volum)数量。
NameSpace Controller
用户通过API Server可以创建新的Namespace并保存在etcd中,Namespace Controller定时通过API Server读取这些Namespace信息。如果Namespace被API标记为优雅删除(即设置删除期限,Deletion Timestamp),则将该Namespace状态设置为“Termination”,并保存到etcd中。同时Namespace Controller删除该Namespace下的Service、RC、Pod、PVC等所有的资源对象。
主要职责:创建和删除Namespace。
Endpoint Controller
EndPoints表示了一个Service对应的所有Pod副本的访问地址,而Endpoints Controller负责生成和维护所有Endpoints对象的控制器。它负责监听Service和对应的Pod副本的变化。
- 如果检测到Service被删除,则删除和该Service同名的Endpoints对象。
- 如果检测到新的Service被创建或修改,则根据该Service信息获得相关的Pod列表,然后创建或更新Service对应的Endpoints对象
- 如果检测到Pod事件,则更新它对应的Service的Endpoints对象。
ServiceController
属于kubernetes集群与外部的云平台之间的一个接口控制器。监听Service变化,如果是一个LoadBalancer类型的Service,则确保外部的云平台上对该Service对应的LoadBalancer实例被相应地创建、删除以及更新路由转发表。
Service、Endpoint、Pod的关系:
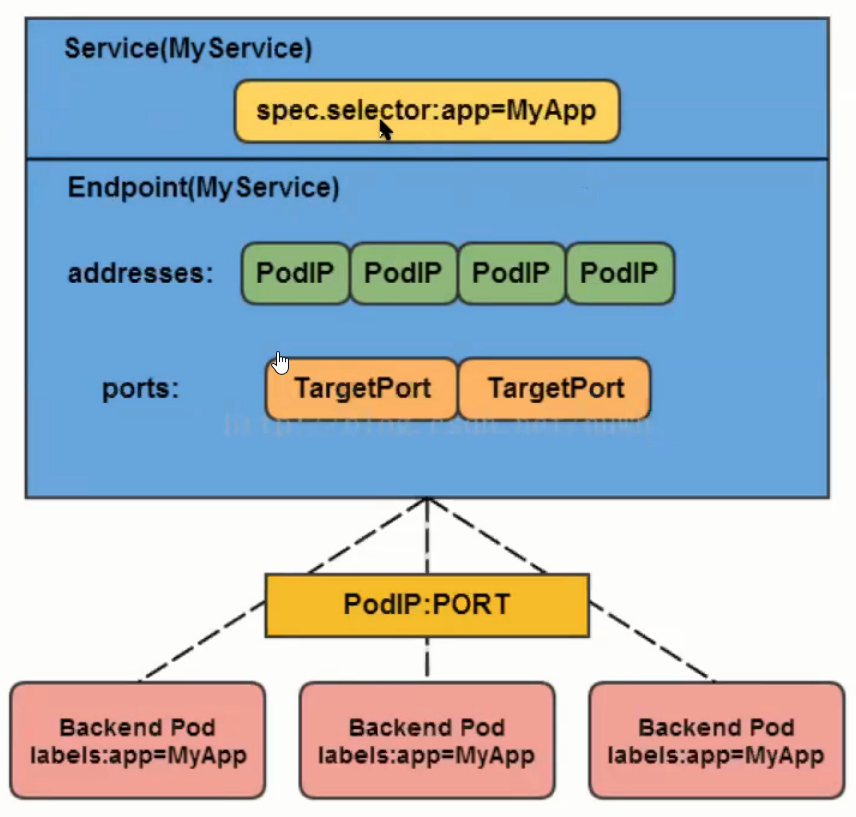
Scheduler
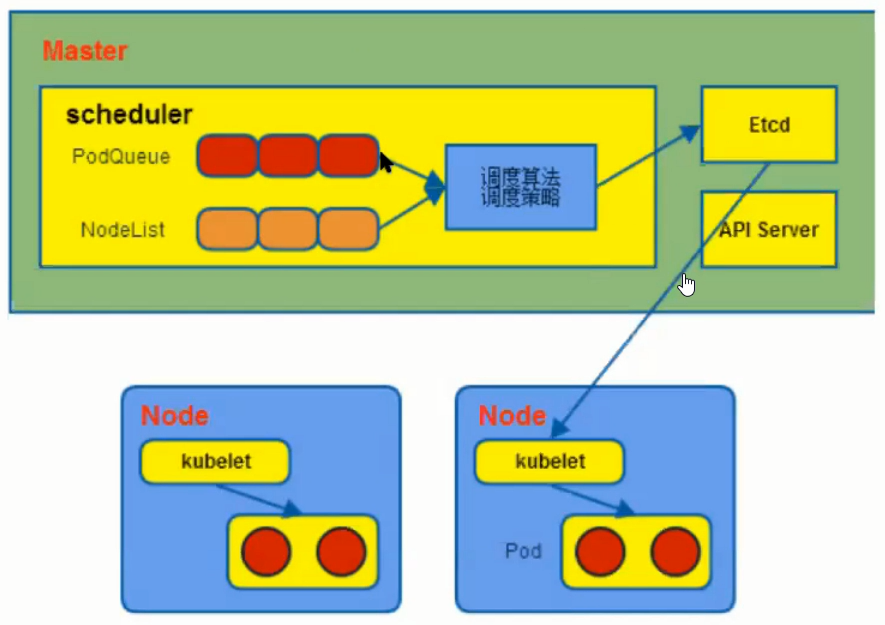
主要负责Pod调度。在整个系统中起承上启下的作用。
承上:负责接收Controller Manager创建的新Pod,为其选择一个合适的Node。通过调度算法为待调度Pod列表的每个Pod从Node列表中选择一个最合适的Node,并将信息写入etcd中。
启下:Node上的kubelet接管Pod的生命周期。kubelet通过API Server监听到kubernets Scheduler产生的Pod绑定信息,然后获取对应的Pod清单,下载Image,并启动容器。
调度流程:
Kubelet
在kubernetes集群中,每个Node节点都会启动kubelet进程,用来处理Master节点下发到本节点的任务,管理Pod和其中的容器。kubelet会在API Server上注册节点信息,定期向Master回报节点资源使用情况,并通过cAdvisor监控容器和节点资源。可以吧kubelet理解成 Server-Agent 架构中的agent,是Node上的Pod管家。
主要职责:节点管理、Pod管理
节点管理
节点通过设置kubelet的启动参数“–register-node”,来决定是否向API Server注册自己,默认为true。可以通过kubelet –help或者查看kubernetes源码 cmd/kubelet/app/server.go中来查看该参数。
默认配置文件在 /etc/kubernetes/kubelet中,其中
- -kubeconfig:用来配置kubeconfig的路径,kubeconfig文件常用来指定证书。
- -hostname-override:用来配置该节点在集群中显示的主机名。
- -node-status-update-frequency:配置kubelet心跳上报的频率,默认为10s。
Pod管理
Kubelet通过API Server获取etcd中自身节点需要的Pod信息,同步到缓存中,根据需求去创建或删除pod。
kubelet创建和修改Pod流程:
- 为该Pod创建一个数据目录。
- 从API Server读取该Pod清单。
- 为Pod挂载外部卷(External Volume)
- 下载Pod用到的Secret。
- 检查运行的Pod,执行Pod未完成的任务。
- 先创建一个Pause容器,该容器接管Pod的网络,再创建其它容器。
- Pod中容器的处理流程:
- 比较容器hash值并做相应处理。
- 如果容器被终止了且没有指定重启策略,则不做处理。
- 调用DockerClient下载容器镜像,调用Docker Client运行容器。
Kubelet执行健康检查:Liveness Probe、Readiness Probe
Liveness Probe:
- 用于判断容器是否存活(running状态)。
- 如果Liveness Probe探针探测到容器非健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应处理。
- 如果容器不包含LivenessProbe探针,则kubelet认为该探针的返回值永远为“success”
Readiness Probe:
- 用于判断容器是否启动完成(read状态),可以接受请求。
- 如果ReadnessProbe探针检测失败,Pod将会被删除。Endpoint Controller将从Service的Endpoint中删除包含该容器所在Pod的endpoint。
探针的三种实现方式:
- Exec Action:在一个容器内部执行一个命令,如果该命令状态返回值为0,则表明容器健康。
- TCP Socket Action:通过容器IP地址和端口号执行TCP检查,如果能够建立TCP连接,则表容器健康。
- HTTP Get Action:通过容器的IP地址、端口号及路径调用HTTP Get方法,如果相应的状态码大于等于200且小于等于400,则认为容器健康。
Kube-proxy
- kube-proxy是管理service的访问入口,包括集群内Pod到Service的访问和集群外访问service。
- kube-proxy管理service的Endpoints,该service对外暴露一个Virtual IP,也成为Cluster IP,集群内通过访问这个Cluster IP:Port就能访问到集群内对应的service下的Pod。
- service是通过Selector选择的一组Pods的服务抽象,其实就是一个微服务,提供了服务的LB和反向代理的能力,而kube-proxy的主要作用就是负责service的实现。
- service另外一个重要作用是,一个服务后端的Pods可能会随着生存灭亡而发生IP的改变,service的出现,给服务提供了一个固定的IP,而无视后端Endpoint的变化。
代理模式:userspace、iptables、ipvs
userspace mode是v1.1及之前版本的默认模式。
iptables mode是v1.10及之前版本的默认模式。
ipvs mode是v1.11及之前版本的默认模式。
userspace
userspace是在用户空间,通过kube-proxy来实现service的代理服务。
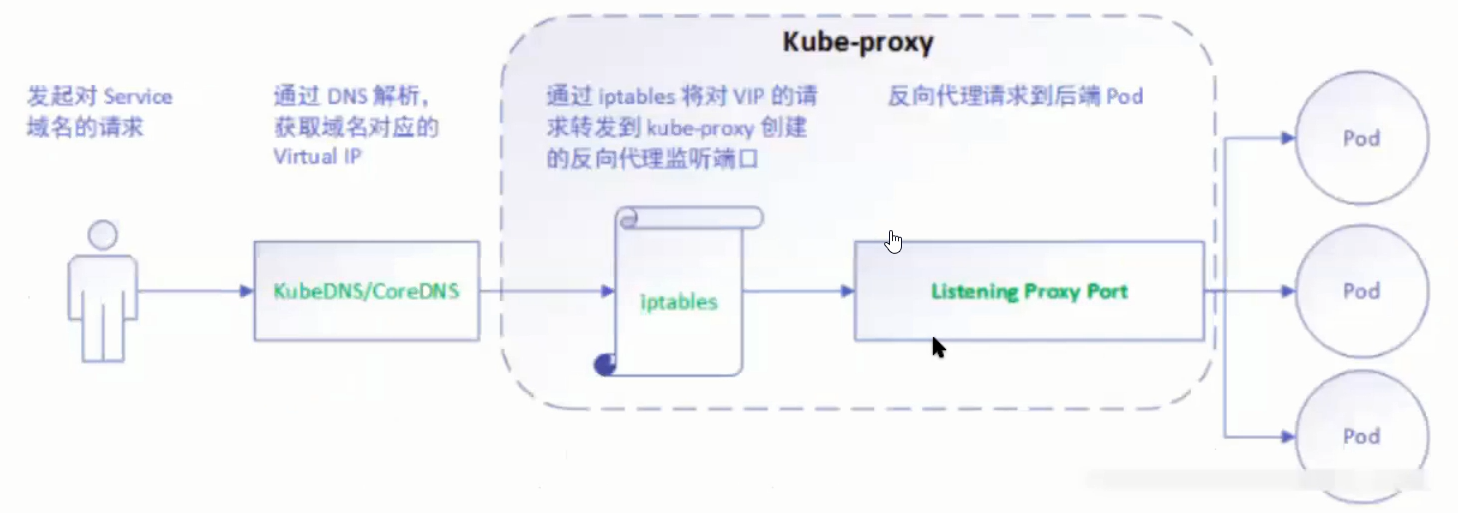
该模式请求在到达iptables进行处理时就会进入内核,而kube-proxy监听则是在用户态,请求就形成了从用户态到内核态再返回到用户态的传递过程,一定程度降低了服务性能。
iptables
iptables模式完全利用内核iptables来实现service的代理和LB。
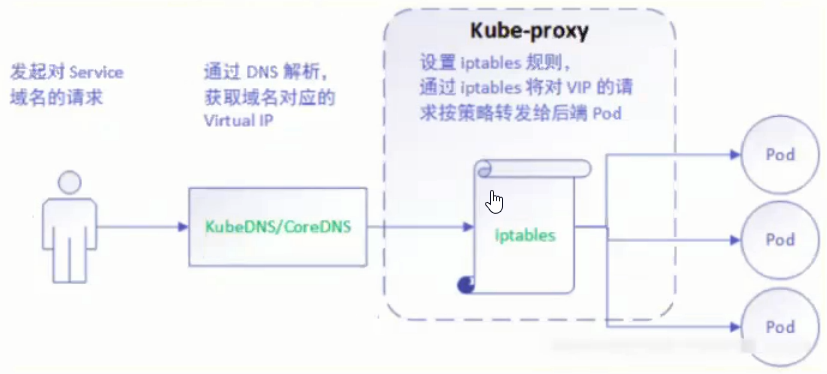
该模式相比userspace模式,克服了请求在用户态-内核态反复传递的问题,性能上有所提升,但使用iptables NAT来完成转发,存在不可忽视的性能损耗,而且在大规模场景下,iptables规划的条目会十分巨大,性能上还要再打折扣。
另外,如果集群中存在上万的service和endpoint,那么node上的iptables rules将会非常庞大,性能还会再大打折扣。这也导致目前大部分企业用k8s上生产时,都不会直接用kube-proxy作为服务代理,二十通过自己开发或者通过Ingress Controller来集成HAProxy,Nginx来代替kube-proxy。
ipvs
在kubernetes 1.8 以上版本中,新增ipvs模式。kube-proxy ipvs是基于NAT实现的,通过ipvs的NAT模式,对访问k8s service的请求进行虚IP的POD IP的转发。当创建一个service后,kubernetes会在每一个节点上创建一个网卡,同时帮你将Service IP(VIP)绑定上,此时相当于每个Node都是一个dns服务器。
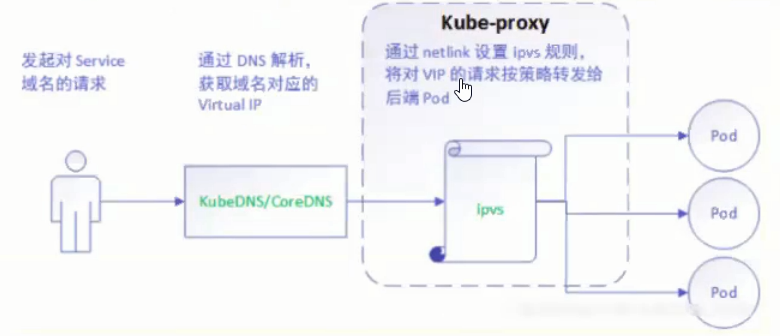
ipvs是目前kube-proxy所支持的最新代理面膜是,相比使用iptables,使用ipvs具有更高的性能。
与iptables、userspace模式一样,kube-proxy 依然监听Service以及Endpoints对象的变化,不过它并不创建反向代理,也不创建大量的iptables规则,二十通过netlink创建ipvs规则,并使用k8s Service与Endpoints信息,对所在节点的ipvs规则进行定期同步;netlink与iptables底层都是基于netfilter钩子,但是netlink由于采用了hash table 而且直接工作在内核态,在性能上比iptables更优。
Kubernetes的网络实现
Kubernetes采用的是基于扁平地址空间的、非NAT的网络模型,每个Pod都有自己唯一的IP地址,网络是由系统管理员或CNI(container network interface)插件建立的,而非k8s本身,k8s并不会要求用户使用指定的网络技术,但是会授权Pod(容器)在不同节点上的相互通信。
- 容器到容器之间的通信。
- Pod到Pod之间的通信。
- Pod到service之间的通信。
- 集群外部与内部服务之间的通信
Kubernetes的网络模型
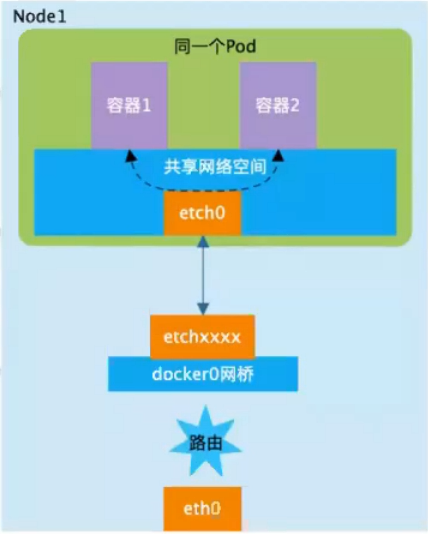
一、同一个POD内容器与容器之间的通信:
Kubernetes使用了一种“IP-per-pod”网络模型:为每一个Pod分配了一个IP地址,Pod内部的容器共享Pod的网络空间,即他们共享Pod的网卡和IP。在同一个Pod内的容器(Pod内的容器是不会跨宿主机的)之间对于网络的各类操作,就和它们在同一台机器上一样,他们甚至可以用localhost地址访问彼此的端口。
二、Pod与Pod之间的通信
两个Pod即有可能运行在同一个Node上,也有可能运行在不同的Node上。所以,可以吧Pod间通信分为两类:
1、同一个Node内的Pod之间的通信
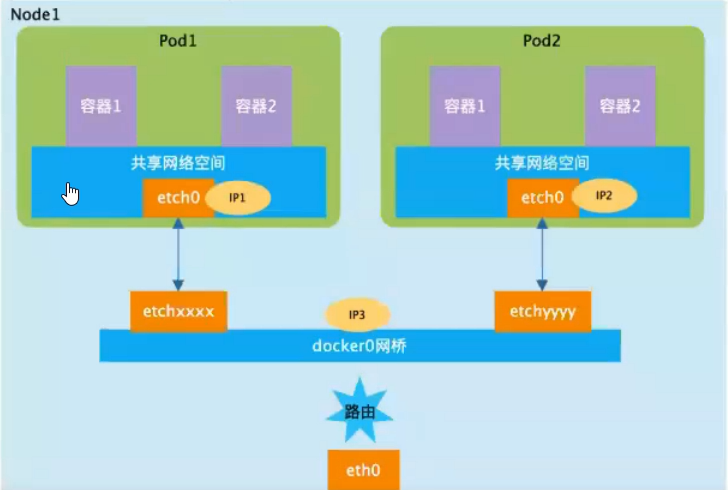
可以看到,Pod1和Pod2都是通信veth pair链接到同一个docker0网桥上,他们的IP地址IP1、IP2都是从docker0网段上动态获取的,他们和网桥本身的IP3是同一个网段的。由于Pod1和Pod2处于同一局域网内,他们之间可以通过docker0作为路由量进行通信。
2、不同Node上的Pod之间的通信
想要实现跨Node的Pod之间的通信,至少需要满足下面三个条件:
- 我们需要知道Pod IP和 Node IP之间的映射关系,通过Node IP转发到Pod IP;
- 在整个Kubernetes集群中对Pod的IP分配不能出现冲突;
- 从Pod中发出的数据包不应该进行NAT地址转换。
CNI(container network interface),这是可选择的,我们这里以Flannel为例。
- 每个主机上安装并运行etcd和flannel;
- 在etcd中规划配置所有主机的docker0子网范围;
- 每个主机上的flannel根据etcd中的配置,为本主机的docker0分配子网,保证所有主机上的docker0网段不重复,并将结果(即本机上的docker0子网信息和本主机IP的对应关系)存入etcd库中,这样etcd库中就保存了所有主机上的docker子网信息和本主机IP的对应关系;
- 当需要与其他主机上的容器进行通信时,查找etcd数据库,找到目的容器的子网对应的outip(目的宿主机的IP);
- 将原始数据包封装在VXLAN或UDP数据包中,IP层以outip为目的IP进行封装;
- 由于目的IP是宿主机IP,因此路由是可达的;
- VXLAN或UDP数据包到达目的宿主机解封装,解出原始数据包,最终到达目的容器。
K8s会记录所有正在运行的pod的IP地址,并将这些信息保存到etcd中(作为Service的Endpoint),这样我们就可以知道Pod IP和Node IP之间的映射关系。
三、Pod和service之间的通信
有两种实现方式:
-
环境变量:当创建一个Pod的时候,kubelet会在该Pod中注入集群内所有Service的相关环境变量。
需要注意:要想一个Pod中注入某个Service的环境变量,则必须Service要比该Pod创建。这一点,几乎使得这种方法进行服务发现不可用
-
DNS:通过coreDNS进行解析。
Pod内的
resolv.conf文件分析:nameserver 10.96.0.10 serach default.svc.cluster.local svc.cluster.local cluster.local options ndots:5Nameserver:
resolv.conf文件的第一行nameserver指定的是DNS服务的IP,这里就是coreDNS的clusterIP。Search域:解析域名的时候,将要访问的域名一次带入search域,进行DNS查询。
Options:指定的是其他项,最常见的是dnots。dnots指的是如果查询的域名包含的店
.小于 5,则先走search域,再用绝对域名;如果查询的域名包含点数大于或等于 5,则先用绝对域名,再走search域。K8s中默认的配合是5。
K8s的域名全称:<service-name>.<namespace>.svc.cluster.local
Pod去访问service时,将会通过DNS解析,最终获取到IP地址。
- 同一Namespace下的service,可以直接通过与域名访问。
- 不同namespace下的service,需要在域名后缀namespace才可访问。
Kubernetes的存储
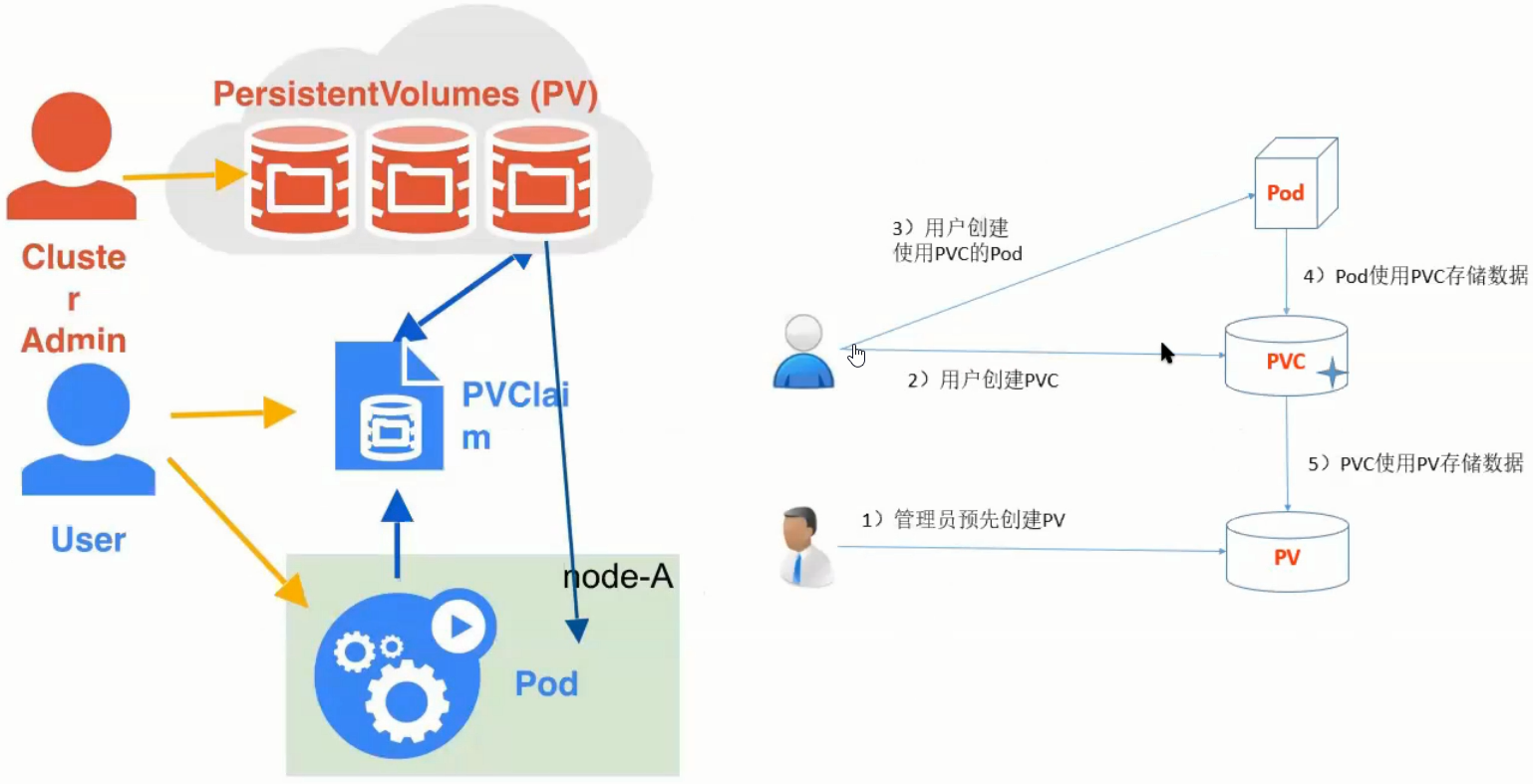
-
Persistent Volume(PV):持久化存储卷,详细定义了预挂载空间的各项参数;
例如,去挂载一个远端的NAS的时候,这个NAS的具体参数就要定义在PV中。一个PV是没有NameSpace限制的,它一般由Admin来创建和维护;
-
Persistent Volume Claim(PVC):持久化存储声明;
它是用户所使用的存储接口,对存储细节无感知,主要是定义一些基本存储的Size、AccessMode参数在里面,并且它是属于某个NameSpace内部的。
-
StorageClass:存储类;
一个动态存储类会按照StorageClass定义的模板来创建一个PV,其中定义了创建模板所需要的一些参数和创建PV的一个Provisioner(就是由谁去创建的)。
配置PV
- 静态:集群管理员创建一些PV。他们带有可供集群用户使用的实际存储的细节。他们存在于Kubernetes API中,可用于消费。
- 动态:当管理员创建的静态PV都不匹配用的PersistentVolumClaim时,集群可能会尝试动态地为PVC创建卷。此配置基于StorageClasses。
绑定PV和PVC
- 当静态时,创建PVC后,将会绑定与之匹配的PV,若没有响应的PV,PVC将无限期地保持待绑定状态,知道匹配的PV出现。
- 当动态时,将会根据storageCloss创建合适的PV,将绑定PVC为之服务。
- 一旦PV和PVC绑定后,PersistentVolumeClaim绑定是排他性的,不管他们是如何绑定的。PVC跟PV绑定是一对一的映射。
使用PVC:
- Pod使用声明作为卷。集群检查声明以查找绑定的卷并为集群挂载该卷。对于支持多种访问模式的卷,用户指定在使用声明作为容器中的卷时所需的模式。
- 用户通过在Pod的volume配置中包含persistentVolumeClaim来调度Pod并访问声明的PV。
- PV对接外部的存储,NFS或者其余文件系统。
保护PVC
- PVC保护的目的是确保由pod正在使用的PVC不会从系统中移除,因为如果被移除的话可能会导致数据丢失。
- 当用户删除了一个pod正在使用的PVC,则该PVC不会被立即删除。PVC的删除将被推迟,直到PVC不再被任何pod使用。
PersistentVolume的回收策略告诉集群在存储卷声明释放后应如何处理该卷。目前,只有NFS和HostPath支持回收策略。AWS EBS、GCE PD、Azure Disk和Cinder卷支持删除策略。
PV回收策略
保留(Retain)、回收(Recycle)、删除(Delete)
保留
保留回收策略允许手动回收资源。当PersistentVolumeClaim被删除时,PersistentVolume任然存在,volume被视为“已释放”。但是由于前一个声明人的数据仍然存在,所有还不能马上进行其他声明。管理员可以通过以下步骤手动回收卷。
- 删除PersistentVolume。在删除PV后,外部基础架构中的关联存储资产(如NFS、GCE PD、Azure Disk或Cinder卷)仍然存在。
- 手动清理相关存储资产上的数据。
- 手动删除关联的存储资产,或者如果要重新使用相同的存储资产,请使用存储资产定义创建新的PersistentVolume。
回收
如果存储卷插件支持,回收策略会在volume上执行基本擦除(rm -rf /thevolume/*),可再次被PVC使用。
- 清除PV中的护具,但是PV不会被删除。
- 该PV可再次被PVC绑定使用。
删除
删除操作将从Kubernetes中删除PersistentVolume对象,并删除外部基础架构(如NFS、GCE PD、Azure Dish或Cinder卷)中的关联存储资产。
- 静态创建的PV,使用的回收策略是创建时配置的。
- 动态创建的PV,使用的回收策略是继承StorageClass中的配置,默认值为DELETE。
实操展示
- 定义一个PV,指定大小为10G,读写模式为单个node读写,回收模式为Retain,后端驱动plugin为NFS。
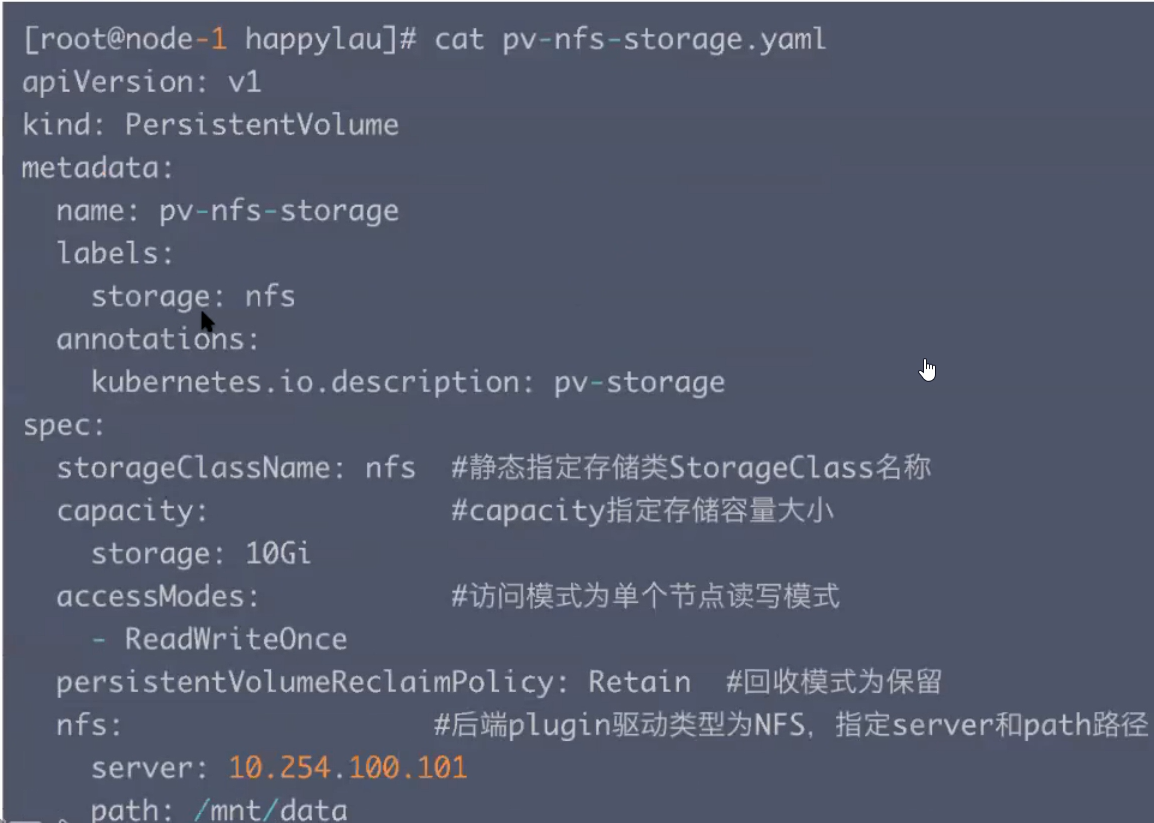
-
创建PersistentVolumes
kubectl apply -f pv-nfs-storage.yaml -
查看PersistentVolumes列表
kubectl get persistentvolumes -
定义PersistentVolumeClaim,通过selector和PV实现关联,指定到相同的StorageClass。
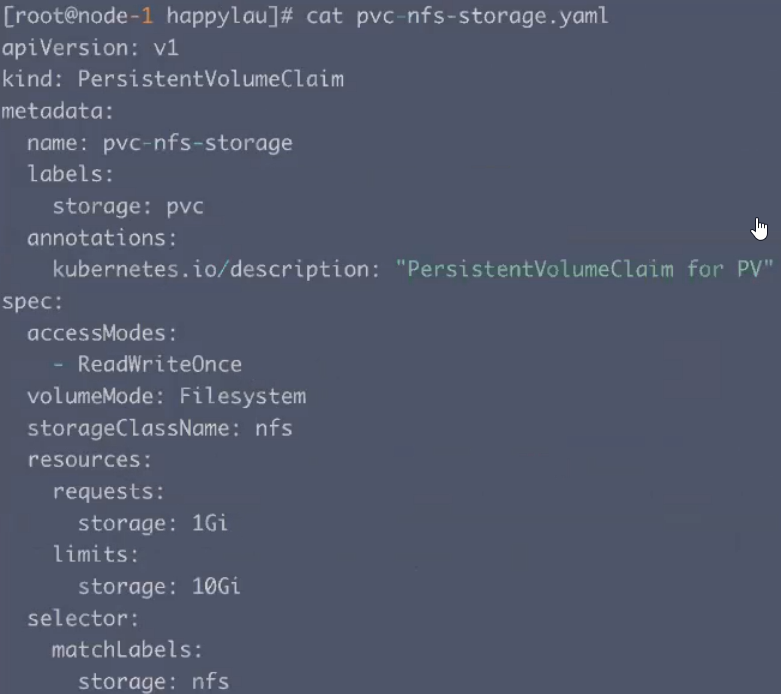
-
生成PersistentVolumeClaim
kubectl apply -f pvc-nfs-storage.yaml -
查看PersistentVolumeClaim列表,通过STATUS可以知道,当前PVC和PV已经Bond关联
kubectl get persistentvolumeclaims -
Pod使用PVC
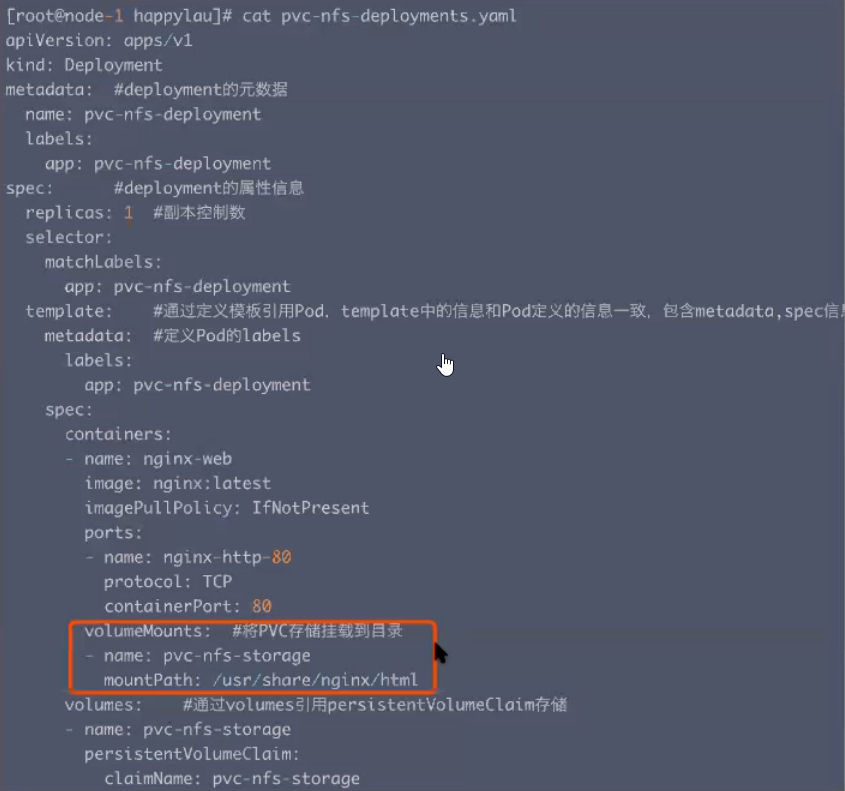
- 此时在pod中读写相应的目录,就会将数据读写到远程的NFS服务器上。
总结:kubernetes中都是用组件解耦的方法进行管理和使用,通过标签的方法很巧妙的联系到一起,各个组件各司其职,实现了功能很强大的集群管理系统。




